Spring boot integrates neo4j to implement a simple knowledge graph
一、neo4j introduction
With the rapid development of social networking, e-commerce, finance, retail, Internet of Things and other industries, the real society has formed a huge and complex network of relationships, and it is difficult for traditional databases to handle relational operations. The relationships between data that need to be processed in the big data industry are growing exponentially with the amount of data. There is an urgent need for a database that supports the calculation of massive and complex data relationships. Graph databases emerged at the historic moment. Many well-known companies in the world are using graph databases, such as: social fields: Facebook, Twitter, Linkedin use it to manage social relationships and implement friend recommendations.
二、Graph database neo4j installation
- download images:
docker pull neo4j:3.5.0 - run docker:
docker run -d -p 7474:7474 -p 7687:7687 --name neo4j-3.5.0 neo4j:3.5.0 - stop docker:
docker stop neo4j-3.5.0 - start docker:
docker start neo4j-3.5.0 - Browser http://localhost:7474/ to access the neo4j management background, the initial account/password neo4j/neo4j, you will be asked to change the initialization password, we changed it to neo4j/123456
三、Getting Started with Simple CQL
Just like we usually use SQL statements in relational databases, neo4j can use Cypher Query Language (CQL) to query graph databases. Let’s briefly take a look at the usage of add, delete, modify, and query.
Add Node
In CQL, you can create a node through the CREATE command. The syntax for creating a node without attributes is as follows:
CREATE (<node-name>:<label-name>)In the CREATE statement, it contains two basic elements, the node name node-name and the label name lable-name. The label name is equivalent to the table name in a relational database, and the node name refers to this piece of data. Taking the following CREATE statement as an example, it is equivalent to creating an empty data without attributes in the Person table.
CREATE (索尔:Person)When creating a node containing attributes, you can append a json string describing the attributes after the label name:
CREATE (
<node-name>:<label-name>
{
<key1>:<value1>,
…
<keyN>:<valueN>
}
)Create a node containing attributes using the following statement:
CREATE (洛基:Person {name:"洛基",title:"诡计之神"})Query Node
After creating the node, we can use the MATCH matching command to query the data of existing nodes and attributes. The format of the command is as follows:
MATCH (<node-name>:<label-name>)Usually, the MATCH command is used later with commands such as RETURN and DELETE to perform specific operations such as return or deletion. Execute the following command:
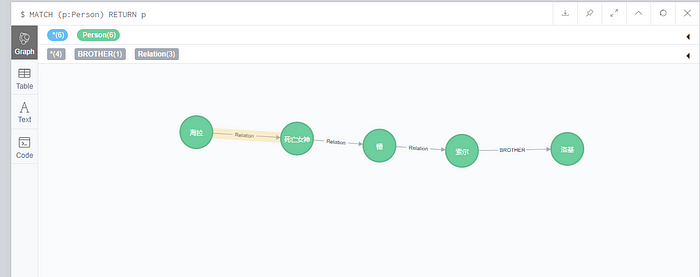
MATCH (p:Person) RETURN pView the visual display results:

You can see that the two nodes added above are empty nodes that do not contain attributes and nodes that contain attributes, and all nodes will have a default generated id as a unique identifier.
Delete Node
Next, we delete the previously created useless nodes that do not contain attributes. As mentioned above, we need to use MATCH with DELETE to delete them.
MATCH (p:Person) WHERE id(p)=100
DELETE pIn this delete statement, an additional WHERE filter condition is used, which is very similar to the WHERE in SQL. The command is filtered by the ID of the node. After the deletion is completed, perform the query operation again, and you can see that only the Loki node is retained.
Add Relationship
In the neo4j graph database, data is stored and managed following the attribute graph model, which means that we can maintain the relationship between nodes. Above, we have created a node, so we need to create another node as both ends of the relationship:
CREATE (p:Person {name:"索尔",title:"雷神"})The basic syntax for creating a relationship is as follows:
CREATE (<node-name1>:<label-name1>)
- [<relation-name>:<relation-label-name>]
-> (<node-name2>:<label-name2>)Of course, you can also use existing nodes to create relationships. Below we use MATCH to query first, and then associate the results to create an association between the two nodes:
MATCH (m:Person),(n:Person)
WHERE m.name='索尔' and n.name='洛基'
CREATE (m)-[r:BROTHER {relation:"无血缘兄弟"}]->(n)
RETURN rAfter the addition is completed, you can query qualified nodes and relationships through relationships:
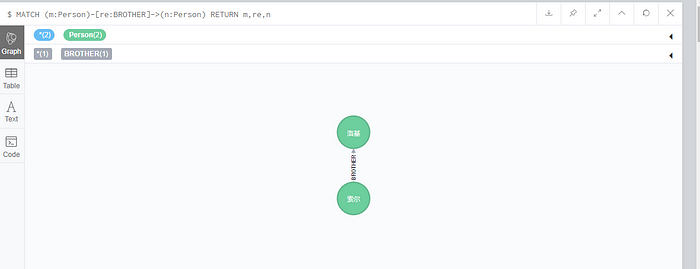
MATCH (m:Person)-[re:BROTHER]->(n:Person)
RETURN m,re,nYou can see that a relationship has been added between the two:
It should be noted that if a node has an association relationship added and simply deletes the node, an error will be reported:
Neo.ClientError.Schema.ConstraintValidationFailed
Cannot delete node<85>, because it still has relationships. To delete this node, you must first delete its relationships.At this time, you need to delete the association relationship when deleting the node:
MATCH (m:Person)-[r:BROTHER]->(n:Person)
DELETE m,rExecuting the above statement will delete the node and the relationships it contains. So, that’s it for getting started with simple cql statements. It can basically meet our simple business scenarios. Now we start integrating neo4j in springboot.
四、springboot integrated neo4j
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>springboot-demo</artifactId>
<groupId>com.et</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>neo4j</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-neo4j</artifactId>
</dependency>
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.2.4</version>
</dependency>
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-parser</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
</project>Application.yaml
server:
port: 8088
spring:
data:
neo4j:
uri: bolt://127.0.0.1:7687
username: neo4j
password: 123456Text SPO extraction
When building a knowledge graph in a project, a large part of the scenarios are based on unstructured data, rather than our manual input to determine the nodes or relationships in the graph. Therefore, we need the ability to extract knowledge based on text. To put it simply, we need to extract SPO subject-predicate-object triples from a piece of text to form the points and edges in the graph. Here we use a ready-made tool class on Git to perform semantic analysis of text and extraction of SPO triples. Project address:https://github.com/hankcs/MainPartExtracto
package com.et.neo4j.hanlp;
import com.et.neo4j.util.GraphUtil;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;
import edu.stanford.nlp.ling.Word;
import edu.stanford.nlp.parser.lexparser.LexicalizedParser;
import edu.stanford.nlp.trees.*;
import edu.stanford.nlp.trees.international.pennchinese.ChineseTreebankLanguagePack;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Collection;
import java.util.LinkedList;
import java.util.List;
/**
* 提取主谓宾
*
* @author hankcs
*/
public class MainPartExtractor
{
private static final Logger LOG = LoggerFactory.getLogger(MainPartExtractor.class);
private static LexicalizedParser lp;
private static GrammaticalStructureFactory gsf;
static
{
//模型
String models = "models/chineseFactored.ser";
LOG.info("载入文法模型:" + models);
lp = LexicalizedParser.loadModel(models);
//汉语
TreebankLanguagePack tlp = new ChineseTreebankLanguagePack();
gsf = tlp.grammaticalStructureFactory();
}
/**
* 获取句子的主谓宾
*
* @param sentence 问题
* @return 问题结构
*/
public static MainPart getMainPart(String sentence)
{
// 去掉不可见字符
sentence = sentence.replace("\\s+", "");
// 分词,用空格隔开
List<Word> wordList = seg(sentence);
return getMainPart(wordList);
}
/**
* 获取句子的主谓宾
*
* @param words HashWord列表
* @return 问题结构
*/
public static MainPart getMainPart(List<Word> words)
{
MainPart mainPart = new MainPart();
if (words == null || words.size() == 0) return mainPart;
Tree tree = lp.apply(words);
LOG.info("句法树:{}", tree.pennString());
// 根据整个句子的语法类型来采用不同的策略提取主干
switch (tree.firstChild().label().toString())
{
case "NP":
// 名词短语,认为只有主语,将所有短NP拼起来作为主语即可
mainPart = getNPPhraseMainPart(tree);
break;
default:
GrammaticalStructure gs = gsf.newGrammaticalStructure(tree);
Collection<TypedDependency> tdls = gs.typedDependenciesCCprocessed(true);
LOG.info("依存关系:{}", tdls);
TreeGraphNode rootNode = getRootNode(tdls);
if (rootNode == null)
{
return getNPPhraseMainPart(tree);
}
LOG.info("中心词语:", rootNode);
mainPart = new MainPart(rootNode);
for (TypedDependency td : tdls)
{
// 依存关系的出发节点,依存关系,以及结束节点
TreeGraphNode gov = td.gov();
GrammaticalRelation reln = td.reln();
String shortName = reln.getShortName();
TreeGraphNode dep = td.dep();
if (gov == rootNode)
{
switch (shortName)
{
case "nsubjpass":
case "dobj":
case "attr":
mainPart.object = dep;
break;
case "nsubj":
case "top":
mainPart.subject = dep;
break;
}
}
if (mainPart.object != null && mainPart.subject != null)
{
break;
}
}
// 尝试合并主语和谓语中的名词性短语
combineNN(tdls, mainPart.subject);
combineNN(tdls, mainPart.object);
if (!mainPart.isDone()) mainPart.done();
}
return mainPart;
}
private static MainPart getNPPhraseMainPart(Tree tree)
{
MainPart mainPart = new MainPart();
StringBuilder sbResult = new StringBuilder();
List<String> phraseList = getPhraseList("NP", tree);
for (String phrase : phraseList)
{
sbResult.append(phrase);
}
mainPart.result = sbResult.toString();
return mainPart;
}
/**
* 从句子中提取最小粒度的短语
* @param type
* @param sentence
* @return
*/
public static List<String> getPhraseList(String type, String sentence)
{
return getPhraseList(type, lp.apply(seg(sentence)));
}
private static List<String> getPhraseList(String type, Tree tree)
{
List<String> phraseList = new LinkedList<String>();
for (Tree subtree : tree)
{
if(subtree.isPrePreTerminal() && subtree.label().value().equals(type))
{
StringBuilder sbResult = new StringBuilder();
for (Tree leaf : subtree.getLeaves())
{
sbResult.append(leaf.value());
}
phraseList.add(sbResult.toString());
}
}
return phraseList;
}
/**
* 合并名词性短语为一个节点
* @param tdls 依存关系集合
* @param target 目标节点
*/
private static void combineNN(Collection<TypedDependency> tdls, TreeGraphNode target)
{
if (target == null) return;
for (TypedDependency td : tdls)
{
// 依存关系的出发节点,依存关系,以及结束节点
TreeGraphNode gov = td.gov();
GrammaticalRelation reln = td.reln();
String shortName = reln.getShortName();
TreeGraphNode dep = td.dep();
if (gov == target)
{
switch (shortName)
{
case "nn":
target.setValue(dep.toString("value") + target.value());
return;
}
}
}
}
private static TreeGraphNode getRootNode(Collection<TypedDependency> tdls)
{
for (TypedDependency td : tdls)
{
if (td.reln() == GrammaticalRelation.ROOT)
{
return td.dep();
}
}
return null;
}
/**
* 分词
*
* @param sentence 句子
* @return 分词结果
*/
private static List<Word> seg(String sentence)
{
//分词
LOG.info("正在对短句进行分词:" + sentence);
List<Word> wordList = new LinkedList<>();
List<Term> terms = HanLP.segment(sentence);
StringBuffer sbLogInfo = new StringBuffer();
for (Term term : terms)
{
Word word = new Word(term.word);
wordList.add(word);
sbLogInfo.append(word);
sbLogInfo.append(' ');
}
LOG.info("分词结果为:" + sbLogInfo);
return wordList;
}
public static MainPart getMainPart(String sentence, String delimiter)
{
List<Word> wordList = new LinkedList<>();
for (String word : sentence.split(delimiter))
{
wordList.add(new Word(word));
}
return getMainPart(wordList);
}
/**
* 调用演示
* @param args
*/
public static void main(String[] args)
{
/* String[] testCaseArray = {
"我一直很喜欢你",
"你被我喜欢",
"美丽又善良的你被卑微的我深深的喜欢着……",
"只有自信的程序员才能把握未来",
"主干识别可以提高检索系统的智能",
"这个项目的作者是hankcs",
"hankcs是一个无门无派的浪人",
"搜索hankcs可以找到我的博客",
"静安区体育局2013年部门决算情况说明",
"这类算法在有限的一段时间内终止",
};
for (String testCase : testCaseArray)
{
MainPart mp = MainPartExtractor.getMainPart(testCase);
System.out.printf("%s\t%s\n", testCase, mp);
}*/
mpTest();
}
public static void mpTest(){
String[] testCaseArray = {
"我一直很喜欢你",
"你被我喜欢",
"美丽又善良的你被卑微的我深深的喜欢着……",
"小米公司主要生产智能手机",
"他送给了我一份礼物",
"这类算法在有限的一段时间内终止",
"如果大海能够带走我的哀愁",
"天青色等烟雨,而我在等你",
"我昨天看见了一个非常可爱的小孩"
};
for (String testCase : testCaseArray) {
MainPart mp = MainPartExtractor.getMainPart(testCase);
System.out.printf("%s %s %s \n",
GraphUtil.getNodeValue(mp.getSubject()),
GraphUtil.getNodeValue(mp.getPredicate()),
GraphUtil.getNodeValue(mp.getObject()));
}
}
}Dynamically build knowledge graph
On the basis of the above, we can dynamically build the knowledge graph in the project. Create a new NodeServiceImpl, which implements two key methods, parseAndBind and addNode. The first is the method of creating nodes in neo4j based on the subject or object extracted from the sentence. Here Determine whether the node already exists based on the name of the node. If it exists, it will be returned directly. If it does not exist, add it:
package com.et.neo4j.service;
import com.et.neo4j.entity.Node;
import com.et.neo4j.entity.Relation;
import com.et.neo4j.hanlp.MainPart;
import com.et.neo4j.hanlp.MainPartExtractor;
import com.et.neo4j.repository.NodeRepository;
import com.et.neo4j.repository.RelationRepository;
import com.et.neo4j.util.GraphUtil;
import edu.stanford.nlp.trees.TreeGraphNode;
import lombok.AllArgsConstructor;
import org.springframework.stereotype.Service;
import sun.plugin.dom.core.Attr;
import java.util.Arrays;
import java.util.List;
import java.util.Objects;
@Service
@AllArgsConstructor
public class NodeServiceImpl implements NodeService {
private final NodeRepository nodeRepository;
private final RelationRepository relationRepository;
@Override
public Node save(Node node) {
Node save = nodeRepository.save(node);
return save;
}
@Override
public void bind(String name1, String name2, String relationName) {
Node start = nodeRepository.findByName(name1);
Node end = nodeRepository.findByName(name2);
Relation relation =new Relation();
relation.setStartNode(start);
relation.setEndNode(end);
relation.setRelation(relationName);
relationRepository.save(relation);
}
private Node addNode(TreeGraphNode treeGraphNode){
String nodeName = GraphUtil.getNodeValue(treeGraphNode);
Node existNode = nodeRepository.findByName(nodeName);
if (Objects.nonNull(existNode))
return existNode;
Node node =new Node();
node.setName(nodeName);
return nodeRepository.save(node);
}
@Override
public List<Relation> parseAndBind(String sentence) {
MainPart mp = MainPartExtractor.getMainPart(sentence);
TreeGraphNode subject = mp.getSubject(); //主语
TreeGraphNode predicate = mp.getPredicate();//谓语
TreeGraphNode object = mp.getObject(); //宾语
if (Objects.isNull(subject) || Objects.isNull(object))
return null;
Node startNode = addNode(subject);
Node endNode = addNode(object);
String relationName = GraphUtil.getNodeValue(predicate);//关系词
List<Relation> oldRelation = relationRepository
.findRelation(startNode, endNode,relationName);
if (!oldRelation.isEmpty())
return oldRelation;
Relation botRelation=new Relation();
botRelation.setStartNode(startNode);
botRelation.setEndNode(endNode);
botRelation.setRelation(relationName);
Relation relation = relationRepository.save(botRelation);
return Arrays.asList(relation);
}
}This article only takes out the key codes for explanation. For specific codes, please refer to the neo4j module in the code warehouse address.
Code Repository
五、Test
Start the java application and enter the following address
http://127.0.0.1:8088/parse?sentence=海拉又被称为死亡女神
http://127.0.0.1:8088/parse?sentence= 死亡女神捏碎了雷神之锤
http://127.0.0.1:8088/parse?sentence=雷神之锤属于索尔Query in the graph database neo4j
MATCH (p:Person) RETURN p